
Since last year, I’ve been developing various multi-agent workflows (orchestrators, sub-agents, worktree isolation, etc.) and despite my best efforts, I kept running into the same problem. My agents would begin well, following my instructions. But as soon as I was dealing with any size of context or complexity of multi-agent workflows I found the agents were ignoring my constraints and at time completely contradicting the instructions provided to them. This is not a case of hallucination, but rather a form of agent amnesia, where it seems to forget the instructions and context it has been provided.
I became curious as to why this was happening and decided to research the topic to understand the cause, and importantly, what actions can be taken to resolve agent amnesia. It goes by other names such as “Lost in the Middle” and “context rot”. Whatever it’s called, the research all points to the same issue: LLMs do not process the information in their context window equally.
The model’s ability to perform decreases as the number of input tokens increases, regardless of the size of the model’s context window. Even with a 1 million token context window, a model may degrade at 50k tokens. Larger context windows do not prevent this degradation; they merely delay it. Anthropic engineers explicitly stated in their September 2025 engineering blog: “you must treat context as a limited resource with decreasing returns.” Models have an attention budget, the amount of context they can focus on without losing the original intention. Every token added to the context window eats into this attention budget. It is a function of how the transformer architecture was designed.
There are three main reasons why an agent experiences this amnesia:
Every Token Compares To All Previous Tokens
All current LLMs use the self-attention mechanism as part of their transformer architecture. For each token the model produces, it compares the new token to all prior tokens within the model’s context window. When there are 1,000 prior tokens, there are 1,000 comparisons. When there are 100,000 prior tokens, there are 100,000 comparisons. This creates attention dilution. Consider attempting to hear one person in a room of ten people versus a room of 10,000 people. Although the person is still speaking, you cannot identify them.

The Location Of A Token In The Context Window Determines The Attention Weight Given To That Token
Most modern LLMs use a technique called RoPE (Rotary Position Encoding) to maintain a record of where tokens are positioned in a sequence. While RoPE works effectively for maintaining local context, it has a documented side effect: the farther apart two tokens are in the sequence, the weaker the attention weight associated with those tokens. This results in a content-independent distance penalty. Relevant information loses its relevance simply due to the physical location of the token relative to the current position in the sequence. In their September 2025 study, Yu et al. demonstrated that RoPE attention is “dominated by the distance between token positions and not by the content.”
As a direct result, Stanford researcher Liu et al. (2023) described the U-shaped performance curve. Models recall information most accurately at the beginning and end of the context window, whereas information located in the middle of the sequence is lost. Their study indicated a 30%+ reduction in accuracy when the model had to locate information previously found at the beginning or end of the prompt in the middle of the prompt. When it comes to agent workflows, this is especially important. Your system prompt is typically located at the beginning of the prompt. The most recent output of a tool is typically located at the end of the prompt. Anything in between (previous tools’ outputs, previous reasoning, etc.) is in a vulnerable area.

Multi-Turn Conversations Worsen The Situation
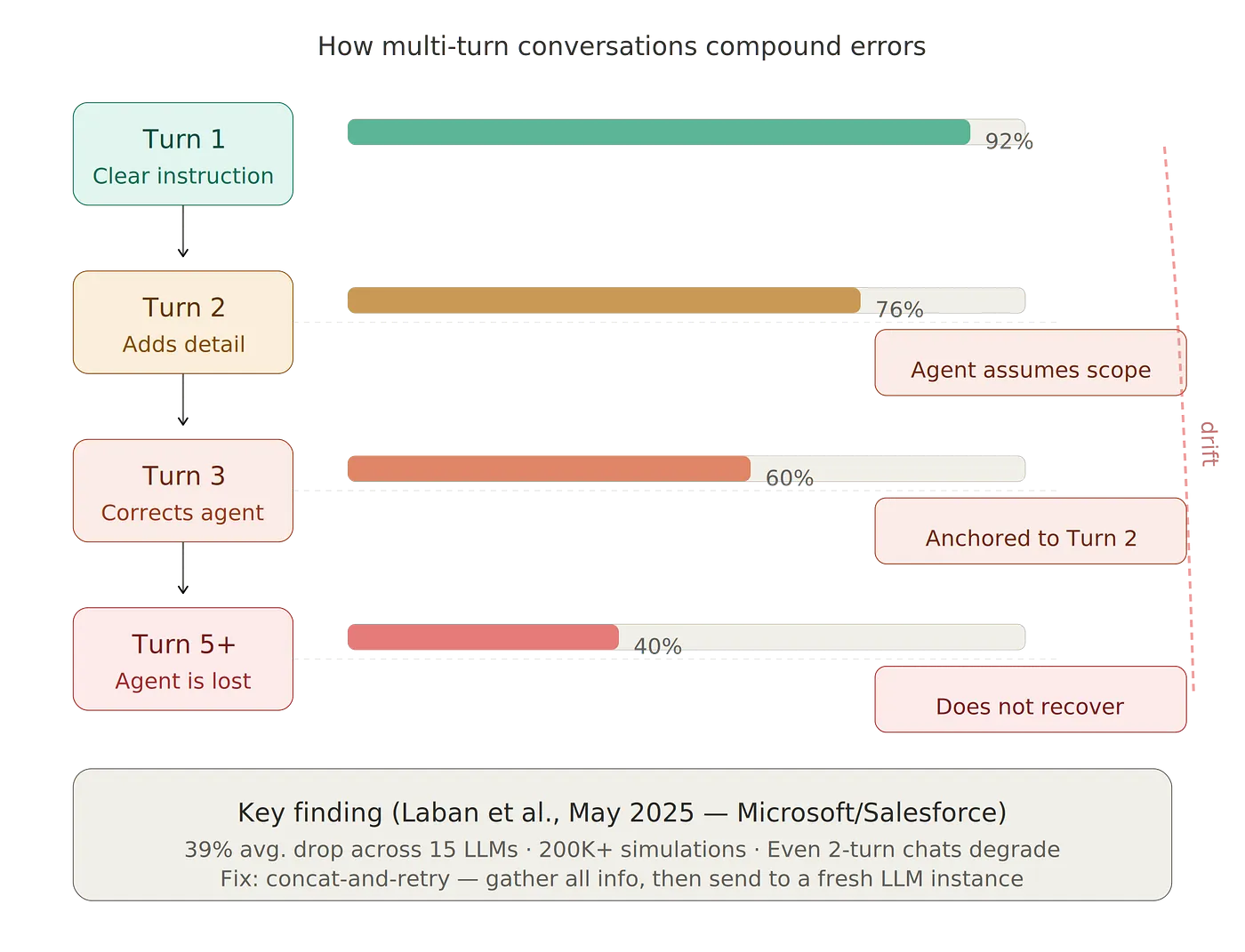
In May 2025 (Laban et al.), researchers at Microsoft Research and Salesforce conducted a joint study involving 200,000+ simulated conversations using 15 LLMs. They reported a 39% performance drop when tasks were distributed across multiple turns as opposed to a single prompt. Models that scored >90% on single-turn tasks dropped to ~60% on multi-turn tasks. The performance degradation occurred even in conversations consisting of only two turns.
The most striking aspect of their findings: once an LLM takes a wrong turn in a conversation, it loses its bearings and never recovers. Incorrect assumptions made during the early parts of a conversation accumulate throughout subsequent turns. The model anchors to its first response and fails to adapt when new information contradicts its initial assumption. Anyone who runs an AI agent through a series of steps — e.g., read a file, analyze it, write code, test it, repair the errors — will encounter this directly. Each additional step adds to the total context and dilutes the agent’s focus on the original instruction.
The Numbers Are More Dire Than You Would Expect
Research indicates and several independent studies present the same picture:
NVIDIA’s RULER benchmark (Hsieh et al., April 2024) evaluated 17 models on retrieval, multi-hop tracing, and aggregation tasks. Although all models claimed to have context windows of 32K tokens or longer, only half performed acceptably at that length.
Chroma’s Context Rot study (Hong, Troynikov, Huber, July 2025) examined 18 frontier models (including GPT-4.1, Claude 4, and Gemini 2.5). The researchers controlled the difficulty of the tasks and varied only the length of the input. Every model suffered a decline in performance. The researchers identified a counterintuitive finding: logically organized documents were actually more difficult to retrieve than randomly ordered text. The model became mired in tracking narrative flow, as opposed to locating the relevant data.
Google’s assessment of Gemini 3 Pro showed MRCR benchmark performance declined from 77% at 128K tokens to 26.3% at 1M tokens. This represents a 50-point decline in performance on Google’s own model.
The common conclusion among the studies mentioned above is that an effective context window is roughly 60–70% of what is claimed, and for tasks requiring actual reasoning (as opposed to simply retrieving keywords), the effective context window is significantly smaller.
Four Patterns That Provide Strong Evidence For Solving The Problem
While building agent workflows, four patterns have solid evidence supporting them.
Pattern 1: Use Sub-Agent Context Isolation
Isolating context for sub-agents is the single most successful strategy in the research. Instead of placing all available data into a single context window, you can delegate to sub-agents that function with their own isolated context windows.
Anthropic provided detailed documentation regarding this in their June 2025 blog entry when they described their multi-agent research platform. The lead agent (Claude Opus 4) coordinates the task and spawns sub-agents (Claude Sonnet 4) for specific research streams. Each sub-agent receives its own isolated context window that contains only the data required for its task. Upon completing its task, the sub-agent sends a summarized version of its findings to the lead agent.
Anthropic reported a 90.2% performance improvement over a single-agent workflow using their multi-agent workflow. Additionally, they determined that token usage accounted for 80% of the performance differences between the two architectures. However, the overall system requires approximately 15 times more tokens. Nonetheless, each agent receives its own isolated and focused context window, as opposed to wading through an accumulation of noise. The key takeaway from their analysis: multi-agent systems work by distributing tokens across distinct context windows, thus increasing the reasoning capabilities of a single agent. The lead agent does not require the complete detail of each sub-agent’s research — it only requires the summarised version of each sub-agent’s findings.
This concept maps directly to any orchestrator-worker architecture. If you are using Claude Code and your task includes researching a code base, planning modifications, implementing those modifications, and testing — each of these tasks can benefit from having its own context window. The implementation task does not require the entire transcript of the research task; it only requires a plan and access to the necessary files.
When designing agent architectures, be cognisant of this: shared context among sub-agents is detrimental to your goal. Manus (the agent framework) applies a principle from Go’s concurrency model here: “share memory by communicating, don’t communicate by sharing memory.” Each sub-agent should receive only the necessary information, and send only its findings back to the lead agent.
Pattern 2: Progressive Compaction
The first of these patterns is Raw vs Compacted. Raw refers to the amount of data in context that remains unchanged — in other words, the original unaltered data. Examples include recent messages, current tool outputs, active instructions, etc. This represents your working set and should remain untouched.
Compacted data refers to information in context that has been stripped of detail but retains enough to allow the agent to recover the missing details via a tool call. For example, the agent may have access to a file containing the full content of the file; however, due to space considerations, only the file path is stored in context. In this case, the agent can use the file path to determine where to locate the file and read the contents via a tool call.
Finally, summarisation represents the lossiest representation of the data in context. Summarization occurs via an LLM and reduces older turn content to a smaller representation. The Manus framework triggers summarization once the total token count exceeds 128K tokens. When summarizing, the most recent 3 turns of content are retained in their raw form to help maintain the model’s “rhythm” (i.e., the model’s format and output quality).
Again, the order of preference is important; i.e., Raw > Compacted > Summarised. As context increases, each subsequent step becomes progressively less precise.
Claude Code performs these operations automatically. The compaction process begins at approximately 83.5% of the context window (approximately 167K tokens of the 200K token context window). Analysis from December 2025 found that 75% utilisation represented the optimal quality point; the remaining 25% was utilised as working memory for the model to perform reasoning. Sessions utilising 90% of available resources generated more raw output but also produced lower-quality code with increased frequency of bugs and inconsistencies in architectural design.
Practically speaking, do not fight the auto-compaction process; instead, learn to work with it. Utilise the /compact instruction to specify custom instructions such as “Preserve code snippets, variable names, and architectural decisions” to guide what survives during compaction. Additionally, prioritise short, focused sessions of 30–45 minutes over longer sessions that generate increasingly greater amounts of noise in the context.
Pattern 3: Concat-and-Retry (Manager-Worker)
This pattern addresses the multi-turn degradation issue directly. It is straightforward and has proven successful.
A “Manager” agent handles the user conversation and gathers the necessary requirements throughout the multi-turn conversation. It will ask clarifying questions to gather constraints and build a complete picture of what is required. However, it does not execute the task.
Once all requirements are collected, the Manager combines all of the information into a single, clean prompt. Then, a new “Worker” LLM instance receives the prompt and executes the task without any prior conversational baggage.
Microsoft/Salesforce reported that the “concat-and-retry” approach recovered nearly 100% of the 39% performance loss caused by multi-turn conversations. The worker begins anew without the accumulated incorrect assumptions, anchors to the earlier attempts, or the diluted attention resulting from the many back-and-forths.
Therefore, for agent workflows, separate your requirement-gathering phase from your execution phase. Do not require the same agent instance to both plan and implement if possible. Gather the plan; then provide a clean prompt to a new instance for implementation.
Prompt-Level Methods
There are several methods that can be employed at the prompt-level to combat context degradation.
Include Important Data at Both the Beginning and the End of the Prompt
Because of the U-shaped attention curve, place your most important instructions at the beginning of the system prompt and reiterate your most important constraints at the end. Do not hide important rules in the middle of a lengthy prompt.
If you are developing RAG systems, this is equally applicable to document ordering. Order documents with the highest relevance at the beginning and end of the context window and those with lower relevance in the middle.
Utilise Structured Formatting
Anthropic’s context engineering white-paper noted that structured formatting of the context window with XML-style tags enables the model to handle larger volumes of context more effectively. Structure is not merely beneficial for clarity; it also facilitates the attention mechanism to parse what is what.
For agent system prompts, utilise clear section dividers. For example:
<task_instructions>
Your core task description here
</task_instructions>
<constraints>
Hard rules the agent must follow
</constraints>
<context>
Background information
</context>
Structured formatting provides the model with explicit structural cues regarding the type of content included in each section as opposed to relying upon the model to infer boundaries based upon a block of text.
Reiterate Key Constraints
If there are constraints that must be preserved across a lengthy session (“never modify files outside the src/ directory” or “always write tests before implementing”), reiterate them. Include them in the system prompt, describe them in your tool definitions, and periodically re-inject them.
While this is a brute-force method, it is effective. You are combating attention dilution by amplifying the signal of critical instructions.
Clear Between Tasks
This is the most basic and least utilised method. Once you transition from one task to another task that is entirely unrelated, clear the context. The previous task’s file contents, error messages, and reasoning are irrelevant to the subsequent task.
In Claude Code: /clear when transitioning tasks. /rename first if you desire to locate the session later, then /resume to resume to it. Old context wastes tokens on each successive message and actively degrades quality.
Maintain Tools Minimally
Each tool definition is retained in context for the duration of the session regardless of whether or not the tool is used. If you have 20 MCP servers connected but require only 3 of the servers to accomplish the current task, you are wasting context on the 17 sets of tool definitions.
Claude Code already addresses this issue — whenever the MCP tool definitions exceed 10% of the context window, Claude Code automatically delays loading the tool definitions and loads them on demand. For custom agent systems, be deliberate regarding the tools that are accessible to each task.
Implications for Agent Developers
The common theme among every study reviewed thus far is: the precision of the items included in the context window is significantly more important than the size of the context window itself. Additional context is not necessarily advantageous. High-signal context is always preferable to low-signal context.
Anthropic’s phrasing encapsulates the concept well — identify the smallest collection of high-signal tokens that maximise the probability of the desired outcome.
For developers creating agent workflows, this translates to the following architectural choices: create isolated sub-agent context, compress aggressively, retrieve just-in-time instead of preloading, and optimise your orchestration such that each phase of work operates within a clean, focused set of tokens.
Although the models are becoming more adept at handling long context windows, the architectural restriction is still present and will not disappear anytime soon. Rather than hope larger context windows will solve the issue, develop solutions that address the restriction and integrate them into your production environments.
If you wish to delve further into the research, the principal studies to review are Liu et al.’s “Lost in the Middle” (arXiv:2307.03172), Chroma’s “Context Rot” report at research.trychroma.com/context-rot, and Anthropic’s context engineering post at anthropic.com/engineering/effective-context-engineering-for-ai-agents.
You may also like
How RailsInsight Gives AI Agents Structural Understanding of Your Rails App)
Ps. if you have any questions
Ask here